[Code] [Paper] [Models] [Codebase Demo Video] [BibTeX]
We introduce Vision-LSTM (ViL), an adaption of xLSTM to computer vision. In order to adjust xLSTM (an autoregressive model) to better handle non-autoregressive inputs such as images, we employ alternating bi-directional mLSTM blocks. Odd blocks process the image row-wise from top left to bottom right, while even blocks process the image from bottom right to top left.

We pre-train ViL models on ImageNet-1K, for which we attach a linear classification head and use the concatenation of the first and last token as input to the classifier. Afterwards, the pre-trained model is evaluated also on transfer classification and semantic segmentation downstream tasks.
Our new model performs favorably against heavily optimized ViT baselines such as DeiT and Vision-Mamba (Vim) on ImageNet-1K classification, ADE20K semantic segmentation and VTAB-1K transfer classification.
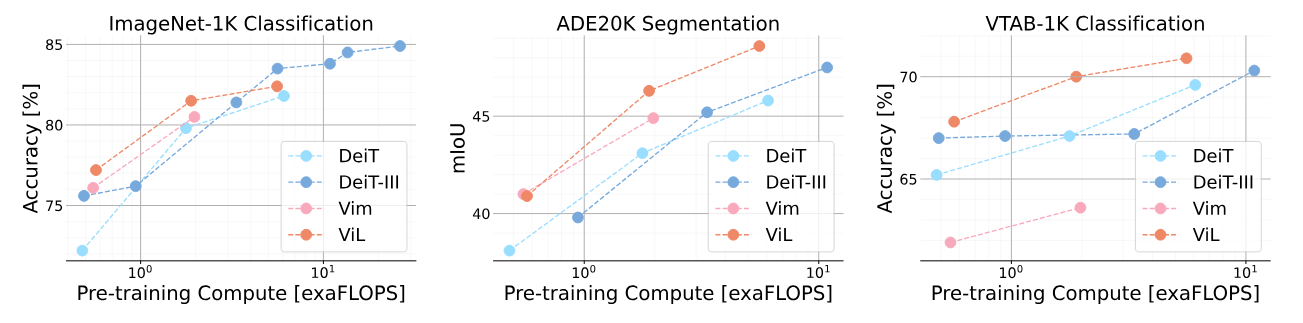
We compare against a variety of isotropic models on ImageNet-1K, where ViL performs best on the tiny and small model scale, outperforming transformers (DeiT), CNNs (ConvNeXt) and vision adaptions of other sequential models such as RWKV (VRWKV) and Mamba (Vim, Mamba®). On the base model scale, ViL achieves good results but heavily optimized transformer models, that underwent multiple cycles of hyperparameter tuning, (DeiT-III) perform best.
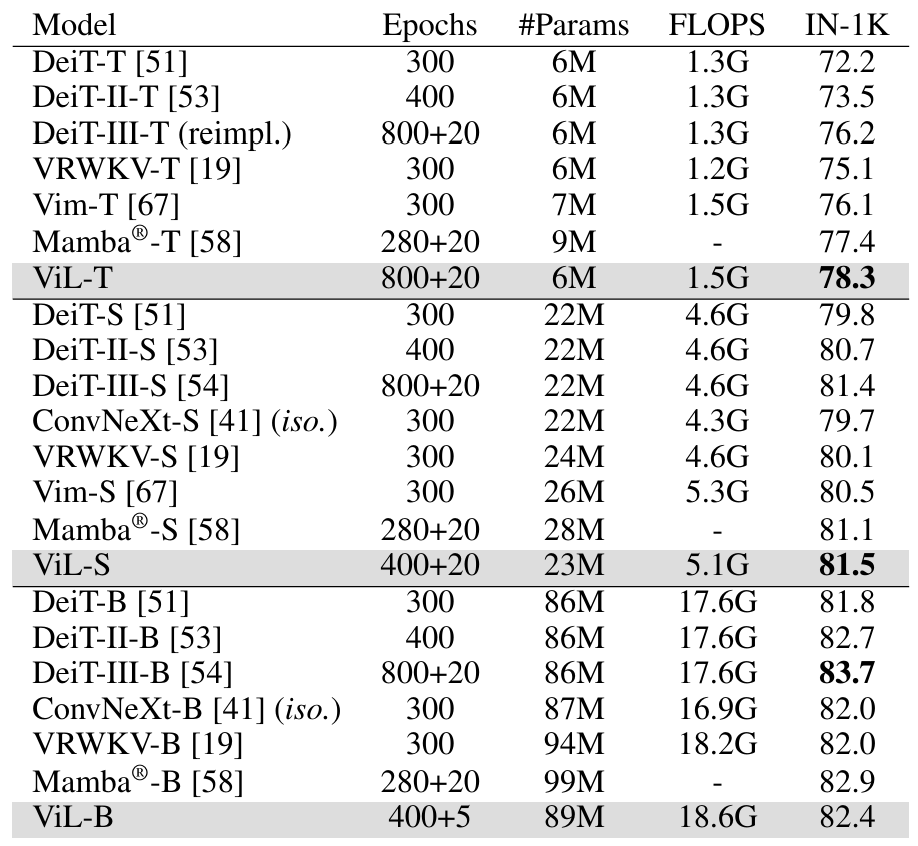
On ADE20K semantic segmentation, ViL also performs very well, even outperforming DeiT-III-B despite the lower ImageNet-1K accuracy.
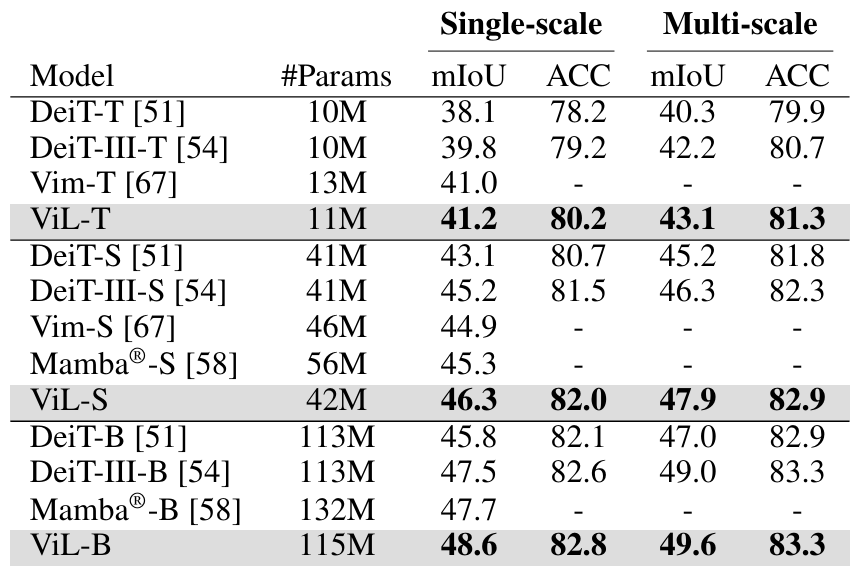
On a diverse set of 19 transfer classification tasks contained in VTAB-1K benchmark, ViL performs best on the average over all 19 datasets. Notably, ViL performs exceptionally well on the 8 structured datasets of the VTAB-1K benchmark, even outperforming DeiT-III-B.